Messung der Variabilität: Ein Überblick
Messung der Variabilität: Ein Überblick!
Bedeutung der Variabilität:
Variabilität bedeutet "Streuung" oder "Ausbreitung". Variabilitätsmaße beziehen sich also auf die Streuung oder Streuung von Scores um ihre zentrale Tendenz. Die Variabilitätsmaße geben an, wie sich die Verteilung über und unter dem zentralen Zahlungsmittel verteilt.
Aus dem folgenden Beispiel können wir eine klare Vorstellung vom Konzept der Variabilitätsmaße bekommen:
Angenommen, es gibt zwei Gruppen. In einer Gruppe gibt es 50 Jungen und in einer anderen Gruppe 50 Mädchen. Diese beiden Gruppen werden einem Test unterzogen. Die mittlere Punktzahl der Jungen und beträgt 54, 4. Bei den Mädchen vergleichen wir die mittlere Punktzahl beider Gruppen. Wir stellen fest, dass es keinen Unterschied in der Leistung der beiden Gruppen gibt. Angenommen, die Bewertungen der Jungen reichen von 20 bis 80 und die Mädchen von 40 bis 60.
Dieser Unterschied in der Reichweite zeigt, dass die Jungen variabler sind, weil sie mehr Gebiete abdecken als die Mädchen. Wenn die Gruppe Individuen mit sehr unterschiedlichen Kapazitäten enthält, werden die Bewertungen von hoch nach niedrig gestreut, der Bereich ist relativ groß und die Variabilität wird groß.
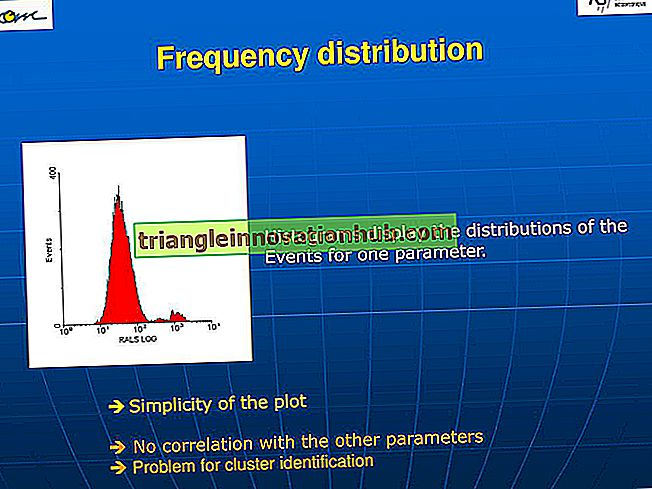
Diese Situation kann in den folgenden Abbildungen grafisch dargestellt werden:

Die obige Abbildung zeigt zwei Häufigkeitsverteilungen für einige Bereiche (N) und einige für den Mittelwert (50), jedoch mit sehr unterschiedlichen Schwankungen. Gruppe A reicht von 20 bis 80 und Gruppe B von 40 bis 60. Gruppe A ist dreimal so variabel wie Gruppe-B-Spreads über die dreifache Entfernung auf der Skala von Scores, obwohl beide Verteilungen eine gewisse Tendenz haben.
Definitionen der Variabilität:
Wörterbuch der Erziehung - Lebenslauf Gut. "Die Streuung oder Variabilität der Beobachtungen einer Verteilung um ein gewisses Maß an zentraler Tendenz." Collins Dictionary of Statistics: "Dispersion ist die Ausbreitung einer Verteilung"
AL Bowley:
"Dispersion ist das Maß für die Variation der Elemente."
Bäche und Schwänze:
„Dispersion oder Spread ist der Grad der Streuung oder Variation der Variablen um einen zentralen Wert.“ Die Eigenschaft, die das Ausmaß angibt, in dem sich die Werte um die zentralen Werte verteilen, wird als Dispersion bezeichnet. Sie weist auch auf die mangelnde Einheitlichkeit der Größe von Verteilungspositionen hin.
Bedarf an Variabilität:
1. Hilft bei der Bestimmung der Abweichungsmaße:
Die Messgrößen der Variabilität helfen uns, den Abweichungsgrad der Daten zu messen. Dadurch können die Grenzen bestimmt werden, innerhalb derer die Daten in messbarer Vielfalt oder Qualität schwanken.
2. Es hilft, verschiedene Gruppen zu vergleichen:
Mit Hilfe von Gültigkeitsmaßstäben können wir die in verschiedenen Einheiten ausgedrückten Originaldaten vergleichen.
3. Es ist sinnvoll, die Informationen zu ergänzen, die durch die Maßnahmen der zentralen Tendenz bereitgestellt werden.
4. Es ist nützlich, auf der Grundlage der Streuungsmaße weitere Vorabstatistiken zu berechnen.
Maße der Variabilität:
Es gibt vier Messgrößen für die Variabilität:
1. Der Bereich
2. Die Quartilabweichung
3. Die durchschnittliche Abweichung
4. Die Standardabweichung
Diese sind:
1. Der Bereich:
Der Bereich ist der Unterschied zwischen einer Serie. Es ist das allgemeinste Maß für Ausbreitung oder Streuung. Es ist ein Maß für die Variabilität der Sorten oder die Beobachtung untereinander und gibt keine Vorstellung von der Verbreitung der Beobachtungen um einen zentralen Wert.
Bereich = H-L
Hier H = Höchste Punktzahl
L = niedrigste Punktzahl
Beispiel:
In einer Klasse haben 20 Schüler die Noten wie folgt gesichert:
52, 48, 43, 60, 55, 25, 15, 45, 35, 68, 50, 70, 35, 40, 42, 48, 53, 44, 55, 52
Hier - Die höchste Punktzahl ist 70
Die niedrigste Punktzahl ist 15
Bereich = H - L = 70 - 15 = 55
Wenn der Bereich höher ist als die Gruppe, zeigt dies eine größere Heterogenität an und wenn der Bereich niedriger ist als die Gruppe, bedeutet dies mehr Homogenität. Der Bereich gibt uns somit einen unmittelbaren und groben Hinweis auf die Variabilität einer Verteilung.
Vorzüge der Reichweite:
1. Die Reichweite ist leicht zu berechnen und leicht zu verstehen.
2. Es ist das einfachste Maß für die Variabilität.
3. Sie liefert eine schnelle Abschätzung des Maßes der Variabilität.
Fehler der Reichweite:
1. Die Reichweite wird stark durch die Schwankung der Ergebnisse beeinflusst.
2. Es basiert nicht auf allen Beobachtungen der Serie. Es werden nur die höchsten und niedrigsten Werte berücksichtigt.
3. Bei Verteilungen mit offenem Ende kann der Bereich nicht verwendet werden.
4. Es wird stark von Schwankungen bei der Probenahme beeinflusst.
5. Es ist stark von extremen Ergebnissen betroffen.
6. Die Serie wird nicht wirklich durch die Reichweite dargestellt. Eine symmetrische und eine symmetrische Verteilung kann den gleichen Bereich haben, jedoch nicht die gleiche Dispersion.
Verwendungsbereiche:
1. Der Bereich wird als Maß für die Streuung verwendet, wenn die Variationen im Wert der Variablen nicht sehr groß sind.
2. Die Reichweite ist das beste Maß für die Variabilität, wenn die Daten zu gestreut oder zu gering sind.
3. Die Reichweite wird verwendet, wenn das Wissen über die extreme Punktzahl oder die Gesamtstreuung gewünscht wird.
4. Wenn eine schnelle Abschätzung der Variabilität gewünscht wird, wird der Bereich verwendet.
2. Die Quartilabweichung (Q):
Neben der Bereichsquellabweichung gibt es ein weiteres Maß für die Variabilität. Sie basiert auf dem Intervall, das die mittleren fünfzig Prozent der Fälle in einer bestimmten Verteilung enthält. Ein Viertel bedeutet 1/4 von etwas, wenn eine Skala in vier gleiche Teile unterteilt ist. "Die Quartilabweichung oder Q ist die Hälfte der Skalenentfernung zwischen dem 75. und 25. Perzentil in einer Häufigkeitsverteilung."
Aus der Abbildung 9.2 haben wir herausgefunden, dass sich das 1. Quartil oder Q 1 in einer Verteilung befindet, unterhalb derer 25% der Fälle liegen und oberhalb der 75% der Fälle liegen. Das 2. Quartil oder Q2 ist eine Position, unterhalb und oberhalb derer 50% der Fälle liegen. Es ist der Median der Verteilung.
Das 3. Quartil oder Qg ist das 75. Perzentil, unter dem 75% der Fälle liegen und über dem 25% liegen. Die Quartilabweichung (Q) ist also die Hälfte der Skalenabstände zwischen dem 3. Quartil (Q 3 ) und dem 1. Quartil (Q 1 ). Es ist auch als Semi-Interquartile Rage bekannt.

Symbolisch:

Um also zuerst die Quartilabweichung zu berechnen, müssen wir das 1. Quartil (Q 1 ) und das 3. Quartil (Q 3 ) berechnen.

Wobei = L = Untergrenze der 1. Quartilklasse,
Die 1. Quartil-Klasse ist die Klasse, deren kumulative Häufigkeit größer als der Wert von N / 4 ist, wenn if vom unteren Ende aus berechnet wird.
N / 4 = ein Viertel der Gesamtzahl der Fälle.
F = Kumulative Häufigkeit des Klassenintervalls unter dem
1. Quartil-Klasse.
Fq 1 = Die Frequenz der Q 1- Klasse
i = Größe des Klassenintervalls 3N

Dabei gilt: L = Untergrenze der 3. Quartilklasse
Die Klasse des 3. Quartils ist die Klasse, deren kumulative Häufigkeit (C f ) größer als der Wert von 3N / 4 ist, dh Cf> 3N / 4, wenn Cf vom unteren Ende aus berechnet wird.
3N / 4 = ¾ von N oder 75% der Gesamtzahl der Fälle.
F = kumulative Häufigkeit der Klasse unterhalb der Klasse.
fq 2 = Die Frequenz der Q 3 -Klasse.
i = Größe des Klassenintervalls
Quartilberechnung aus Gruppendaten:
Beispiel:
Ermitteln Sie die Quartilabweichung der folgenden Daten:

Schritte zur Berechnung der Quartilabweichung:
Schritt 1:
Berechnen Sie N / 4 dh 25% der Verteilung und 3N / 4 dh 75% der Verteilung.
Hier ist -N = 50, also N / 4 = 12, 5
und 3N / 4 = 37, 5
Schritt 2:
Berechnen Sie das C f vom unteren Ende. Wie in Tabelle 9.1 Spalte 3.
Schritt 3:
Finden Sie die Klasse Q 1 und Q 3 heraus .
In diesem Beispiel:
Ci, 60—64 ist Q1-Klasse, weil C f > N / 4 ist
Ci 75—79 ist Q 3 Klasse, weil
der Cf> 3N / 4
Schritt 4:
Finden Sie heraus, ob F für die Klassen Q 1 und Q 3 geeignet ist. In diesem Beispiel
F für die Klasse Q 1 = 10
F für Q3-Klasse = 30 Schritt
Schritt 5:
Finden Sie Q1 heraus, indem Sie die obigen Werte in die Formel eingeben.
Q 1 = L + N / 4 - F / fq1 xi
Hier ist L = 59, 5, da die genauen Grenzen der Q 1- Klasse 60–64 59, 5–64, 5 sind.
F = 10 der Cf unter der Q1-Klasse
Fq 1 = 4: die genaue Häufigkeit der Klasse Q 1
i = 5, Größe des Klassenintervalls
N / 4 = 12, 5
Nun ist Q 1 = 59, 5+ 12, 5-10 / 4 x 5
= 59, 5 + 2, 5 / 4 x 5
= 59, 5 + 0, 63 x 5
= 59, 5 + 3, 13 = 62, 63
Schritt 6:
Finden Sie das Q 3 heraus, indem Sie die Werte in die Formel eingeben.
Hier ist L = 74, 5, da die genauen Grenzen der Klasse Q 3 75–79 74, 5–79, 5 sind.
F = 30 der Cf unter der Q3-Klasse.
3N / 4 = 37, 5
Fq 1 = 8 die genaue Häufigkeit der Klasse Q 3 .
i = 5 Größe der Klassenintervalle.
Q 3 = 74, 5 + 37, 5–30 / 8 × 5
= 74, 5 + 7, 5 / 8 × 5 = 74, 5 + 0, 94 × 5
= 74, 5 + 4, 7 = 79, 2
Schritt 7:
Finden Sie Q heraus, indem Sie den obigen Wert in die Formel eingeben.
Q = Q 3 -Q 1/2 = 79, 2 - 62, 63 / 2
= 16, 5 / 2 = 8, 285 = 8, 29
Vorzüge der Quartilabweichung:
1. Die Quartilabweichung ist einfach zu berechnen und leicht zu verstehen.
2. Es ist repräsentativer und vertrauenswürdiger als Reichweite. Im Falle offener Klassenintervalle wird es zur Untersuchung von Dispersionsmessungen verwendet.
3. Bei Intervallen mit offenem Ende wird es zur Untersuchung von Dispersionsmessungen verwendet.
4. Es ist ein guter Index für die Score-Dichte in der Mitte der Verteilung.
5. Wenn wir den Median als Maß für die zentrale Tendenz zu diesem Zeitpunkt nehmen, ist Q als Maß für die Dispersion bevorzugt.
6. Wie die Reichweite wird es nicht von extremen Ergebnissen beeinflusst.
Fehler der Quartilabweichung:
1. Es basiert nicht auf allen Beobachtungen von Daten. Die ersten 25% und die letzten 25% der Ergebnisse werden ignoriert.
2. Eine weitere algebraische Behandlung ist bei Q nicht möglich. Es handelt sich lediglich um einen Positionsmittelwert. Die Variation der Werte einer Variablen von einem Durchschnitt wird nicht untersucht. Es zeigt lediglich eine Entfernung auf einer Skala an.
3. Sie wird durch Schwankungen der Ergebnisse beeinflusst. Ihr Wert wird auf jeden Fall durch eine Änderung des Wertes einer einzelnen Partitur beeinflusst.
4. Q ist kein geeignetes Maß für die Streuung, wenn in einer Reihe die Werte verschiedener Wertungen stark variieren.
Verwendung der Quartilabweichung:
1. Wenn der Median zu dieser Zeit das Maß der zentralen Tendenz ist, wird Q als Streuungsmaß verwendet.
2. Wenn extreme Bewertungen SD betreffen oder die Bewertungen zu diesem Zeitpunkt verstreut sind, wird Q als Maß für die Variabilität verwendet.
3. Wenn unser Hauptinteresse darin besteht, die Konzentration um den Median zu wissen - die mittleren 50% der Fälle, wird zu diesem Zeitpunkt Q verwendet.
4. Wenn die Klassenintervalle offen sind, wird Q als Dispersionsmaß verwendet.
3. Die durchschnittliche Abweichung (AD):
Wir haben über zwei Variabilität gesprochen, die Reichweite und die Abweichung des Quartils. Keine dieser Dispersionen gibt jedoch Auskunft über die Zusammensetzung der Verteilung. Dies liegt daran, dass beide Dispersionen nicht alle Einzelwerte berücksichtigen. Wir können einige der gravierenden Mängel der Reichweiten- und Quartilabweichung überwinden, indem wir eine andere Dispersion verwenden, die als durchschnittliche Abweichung oder mittlere Abweichung bezeichnet wird.
"Die durchschnittliche Abweichung ist das arithmetische Mittel aller Abweichungen verschiedener Bewertungen vom Mittelwert der Bewertungen ohne Berücksichtigung des Vorzeichens der Abweichung."
Daher ist das arithmetische Mittel der Durchschnittsabweichung der Abweichungen einer Reihe, die aus einem bestimmten Maß der zentralen Tendenz berechnet wird. Die durchschnittliche Abweichung ist also der Mittelwert der Abweichungen von ihrem Mittelwert (manchmal von Median und Modus).
Definitionen:
Collins Wörterbuch der Statistik:
"Die durchschnittliche Abweichung ist der Mittelwert der absoluten Werte der Differenzen zwischen den Werten einer Variablen und dem Mittelwert ihrer Verteilung."
Wörterbuch der Ausbildung, Lebenslauf Gut:
"Ein Maß, das den durchschnittlichen Betrag ausdrückt, um den die einzelnen Elemente in einer Verteilung von einem Maß der zentralen Tendenz wie dem Mittelwert abweichen."
ER Garrett:
"Die durchschnittliche Abweichung oder AD ist der Mittelwert der Abweichungen aller einzelnen Bewertungen einer Serie von ihrem Mittelwert (gelegentlich vom Median oder Modus)."
Man kann also sagen, dass die mittlere Abweichung oder mittlere Abweichung, wie sie genannt wird, der Mittelwert der Abweichungen aller Bewertungen ist.
Zeichen und alle Abweichungen, ob + ve oder - werden als positiv behandelt, werden nicht berücksichtigt.

wobei AD = durchschnittliche Abweichung
£ = Capital Sigma, Summe Summe von
II = Modulous in short Mod, bedeutet kein negatives Vorzeichen.
x = Abweichung (X - M)
Berechnung der durchschnittlichen Abweichung:
Es gibt zwei Situationen zur Berechnung der durchschnittlichen Abweichung:
(a) Wenn die Daten nicht gruppiert werden.
(b) Wenn Daten gruppiert werden.
Berechnung von AD aus nicht gruppierten Daten.
Beispiel:
Finden Sie AD der folgenden 10 Ergebnisse:
23, 34, 16, 27, 28, 39, 45, 26, 18, 27
Lösung:
Schritt 1:
Ermitteln Sie den Mittelwert der Ergebnisse mit der Formel
∑X / N

Schritt 2:
Ermitteln Sie die Abweichung aller Ergebnisse und ziehen Sie den Mittelwert von den Ergebnissen ab.
Schritt 3:
Ermitteln Sie die absolute Abweichung wie in Tabelle 9.2 und dann ∑ | x |

Schritt 4:
Geben Sie die Werte in die Formel ein.

Die AD = 7, 58.
Berechnung der AD aus gruppierten Daten:
Beispiel:
Finden Sie die AD der folgenden Daten heraus:

Lösung :
Schritt 1:
Ermitteln Sie den Mittelwert der Verteilung.
Mittelwert = 70, 80

Schritt 2:
Ermitteln Sie den Mittelpunkt für jedes Klassenintervall. Wie in Spalte -3 der Tabelle -9.3
Schritt 3:
Ermitteln Sie das x, indem Sie den Mittelwert vom Mittelpunkt (X) abziehen. Wie in Spalte -5 der Tabelle 9.3 gezeigt.
Schritt 4:
Ermitteln Sie die absolute Abweichung oder | x |. Wie oben in Spalte 6.
Schritt 5:
Finden Sie heraus, | f x |. durch Multiplikation von f mit | x. Wie in Spalte —7 gezeigt und finden Sie Σ | f x |.
Schritt-6:
Geben Sie die obigen Werte in die Formel ein.
Die Formel für AD aus gruppierten Daten

Wobei = AD = durchschnittliche Abweichung
Σ = Summe von
f = Frequenz
x = Abweichung dh (X - M)
N = Gesamtzahl der Fälle, dh ∑ f .
Werte in die Formel setzen

Verdienste von AD:
1. Die durchschnittliche Abweichung ist fest definiert und ihr Wert ist genau und eindeutig.
2. Es ist leicht zu berechnen.
3. Es ist leicht zu verstehen. Denn es ist der Durchschnitt der Abweichungen von einem Maß der zentralen Tendenz.
4. Es basiert auf allen Beobachtungen.
5. Der Wert extremer Ergebnisse wird weniger beeinflusst.
Fehler der AD:
1. Der gravierendste Nachteil bei der durchschnittlichen Abweichung besteht darin, dass die Vorzeichen der Abweichungen ignoriert werden, was den Grundregeln der Mathematik widerspricht.
2. Eine weitere algebraische Behandlung ist bei AD nicht möglich.
3. Es wird sehr selten verwendet. Wegen der Standardabweichung wird im Allgemeinen als Dispersionsmaß verwendet.
4. Bei Berechnung aus dem Modus AD ergibt sich kein genaues Maß für die Dispersion.
Verwendung der durchschnittlichen Abweichung:
1. Die durchschnittliche Abweichung wird verwendet, wenn alle Abweichungen vom Mittelwert nach ihrer Größe gewichtet werden sollen.
2. Wenn extreme Werte zu diesem Zeitpunkt die Standardabweichung beeinflussen, ist AD das beste Maß für die Streuung.
3. AD wird verwendet, wenn wir wissen wollen, inwieweit sich die Maße auf beiden Seiten des Mittelwerts ausbreiten.
4. Die Standardabweichung (SD):
Wir haben drei Messgrößen der Variabilität besprochen, nämlich Reichweite, Quartilabweichung und durchschnittliche Abweichung. Wir haben auch festgestellt, dass alle unter gravierenden Nachteilen leiden.
Der Bereich wird nur berücksichtigt, um nur die höchste Punktzahl und die niedrigste Punktzahl zu berücksichtigen. Die Quartilabweichung berücksichtigt nur die mittleren 50% der Bewertungen, und bei einer durchschnittlichen Abweichung ignorieren wir die Vorzeichen.
Um all diese Schwierigkeiten zu überwinden, verwenden wir ein anderes Dispersionsmaß, das als Standardabweichung bezeichnet wird. Es wird häufig in der experimentellen Forschung verwendet, da es der stabilste Variabilitätsindex ist. Symbolisch wird es als σ (griechischer Kleinbuchstabe Sigma) geschrieben.
Definitionen:
Collins Statistikwörterbuch.
„Die Standardabweichung ist ein Maß für die Streuung oder Streuung. Es ist die mittlere quadratische Abweichung. "
Wörterbuch der Erziehung - Lebenslauf Gut.
"Ein weit verbreitetes Maß für die Variabilität, bestehend aus der Quadratwurzel des Durchschnitts der quadratischen Abweichungen der Bewertungen vom Mittel der Verteilung."
Die Standardabweichung ist die Quadratwurzel des Durchschnittswertes der quadrierten Abweichungen der Bewertungen von ihrem arithmetischen Mittelwert.
Die SD wird berechnet, indem die quadratische Abweichung jedes Messwerts aus dem Mittelwert dividiert durch die Anzahl der Fälle addiert wird und die Quadratwurzel extrahiert wird. Um es klarer zu machen, sollten wir hier beachten, dass wir bei der Berechnung des SD alle Abweichungen separat quadrieren, ihre Summe ermitteln, die Summe durch die Gesamtzahl der Bewertungen dividieren und dann die Quadratwurzel des Durchschnitts der quadratischen Abweichung ermitteln. Daher wird es auch als "quadratische Abweichung" bezeichnet.
Das Quadrat der Standardabweichung wird als Varianz (σ 2 ) bezeichnet. Es wird als mittlere quadratische Abweichung bezeichnet. Sie wird auch als Dispersion des zweiten Moments bezeichnet.
Berechnung von SD aus nicht gruppierten Daten:
Beispiel:
Ermitteln Sie den SD der folgenden Daten:
6, 8, 10, 12, 5, 8, 9, 17, 20, 11.
Lösung:
Schritt 1:
Ermitteln Sie den Mittelwert der Ergebnisse.
Schritt 2:
Ermitteln Sie die Abweichung (x) der einzelnen Punkte.


Berechnung von SD aus gruppierten Daten:
In gruppierten Daten kann SD auf zwei Arten berechnet werden:
1. Direkte Methode oder Lange Methode
2. Kurze Methode oder Angenommene Mittelmethode
1. Direkte Methode oder Lange Methode:
Beispiel:
Finden Sie den SD der folgenden Distribution heraus:

Lösung:
Schritt 1:
Ermitteln Sie den Mittelpunkt jedes Klassenintervalls. (Colum-3-Tabelle 9.4)

Schritt 2:
Ermitteln Sie den Mittelwert der Verteilung:
Hier ist M = ∑ f x / N = 3540/50
= 70, 80
Schritt 3:
Ermitteln Sie die Abweichung (x), indem Sie den Mittelwert von den Punkten abziehen.
Schritt 4:
Finden Sie das f x heraus, indem Sie f (col-2) mit x (col-5) multiplizieren.
Schritt 5:
Finden Sie das f x heraus, indem Sie f x (col-2) mit x (col-5) multiplizieren.
Schritt-6:
Berechnen Sie ∑ f x, indem Sie die Werte in col-7 addieren.
Schritt-7:
Geben Sie die Werte in die Formel ein.

2. Kurzmethode oder angenommene Mittelmethode:
Kurz gesagt, die Berechnung von SD ist einfach und weniger zeitaufwändig. Wenn die Mittelpunkte der Klassenintervalle Dezimalzahlen sind, wird es schwieriger, SD in einer langen Methode zu berechnen. Diese Methode besteht im Wesentlichen darin, einen Mittelwert zu "erraten" oder anzunehmen und später eine Korrektur durchzuführen, um den tatsächlichen Mittelwert zu ermitteln. Damit wird es als vermutete Mittelmethode bezeichnet.
Beispiel:
Berechnen Sie den SD der folgenden Verteilung:

Lösung:
Schritt 1:
Nehmen Sie den Mittelpunkt eines beliebigen Klassenintervalls als angenommenen Mittelwert an. Es ist jedoch besser anzunehmen, dass der Mittelpunkt des Klassenintervalls in der Mitte die höchste Häufigkeit als angenommenen Mittelwert hat. Hier sei angenommen = 72 als Angenommener Mittelwert.
Schritt 2:
Ermitteln Sie x (Abweichung der Ergebnisse vom angenommenen Mittelwert), wie in Spalte 3 dargestellt.
x '= X - M / i

Schritt 3:
Berechne f x 'durch Multiplikation von x' mit f (col-4).
Schritt 4:
Berechne f x 2 durch Multiplizieren von x '(col-3) mit f x (col-5).
Schritt 5:
Finden Sie ∑ f x 'und ∑ f x ' 2 it ', indem Sie die Werte in col-4 bzw. col-5 addieren. '
Schritt-6:
Geben Sie die Werte in die Formel ein:
Kurzformel für SD lautet:

Dabei ist i = Größe des Klassenintervalls
∑ = Summe von
f = Frequenz
x '= Abweichung der Bewertungen von ihrem angenommenen Mittelwert.

Wenn wir nun ∑ f x '/ N anstelle von C einsetzen
Die Formel lautet wie folgt:

Jetzt setzen wir die Werte in eine Formel, die wir bekommen.

1.Wird jeder Punktzahl ein konstanter Wert hinzugefügt oder von jeder Punktzahl abgezogen, bleibt der Wert von SD unverändert:
Das bedeutet, SD ist unabhängig von der Ursprungsänderung (Addition, Subtraktion). Wenn also von jeder Sorte ein konstanter Wert addiert oder abgezogen wird, bleibt der SD derselbe.
Wir können dies anhand des folgenden Beispiels untersuchen:

In der obigen Tabelle sind Punktzahlen von 5 Schülern angegeben. Lassen Sie uns sehen, was mit dem SD der Scores geschieht, wenn wir eine konstante Zahl addieren, sagen wir 5 und subtrahieren Sie 5 von jedem Score.

2. Wenn ein konstanter Wert mit den ursprünglichen Bewertungen multipliziert oder dividiert wird, wird der Wert von SD mit der gleichen Zahl multipliziert oder dividiert:
Dies bedeutet, dass der SD unabhängig von Skalenänderungen ist (Multiplikation, Division). Wenn wir die Originalwerte mit einer konstanten Zahl multiplizieren, wird die SD auch mit derselben Zahl multipliziert.
Wenn wir wieder jede Punktzahl durch eine konstante Zahl teilen, wird die SD auch durch dieselbe Zahl geteilt.
Wir können dies mit dem folgenden Beispiel veranschaulichen:

In der obigen Tabelle sind Punktzahlen von 5 Schülern angegeben. Lassen Sie uns sehen, was mit dem SD der 5 Scores geschieht, wenn wir es mit einer konstanten Zahl, beispielsweise 2, multiplizieren und mit derselben konstanten Zahl teilen.

Daraus haben wir herausgefunden, dass, wenn die Bewertungen mit einer konstanten Zahl multipliziert werden, auch σ mit dieser multipliziert wird. Wenn die Bewertungen durch eine konstante Zahl geteilt werden, wird auch das σ durch dieselbe Zahl geteilt.
Vorzüge von SD:
1. Die Standardabweichung ist fest definiert und ihr Wert ist immer eindeutig.
2. Es basiert auf allen Beobachtungen von Daten.
3. Sie kann weiter algebraisch behandelt werden und besitzt viele mathematische Eigenschaften.
4. Im Gegensatz zu Q und AD ist es weniger von Schwankungen der Ergebnisse betroffen.
5. Im Gegensatz zu AD werden die negativen Vorzeichen nicht ignoriert. Durch das Ausgleichen von Abweichungen werden diese Schwierigkeiten überwunden.
6. Es ist das verlässlichste und genaueste Maß für die Variabilität. Es geht immer um den Mittelwert, der das stabilste Maß der zentralen Tendenz darstellt.
7. SD gibt ein Maß an, das von einem Test zum anderen eine vergleichbare Bedeutung hat. Vor allem die normalen Kurveneinheiten werden in einer Einheit ausgedrückt.
Nachteile von SD:
1. SD ist schwer zu verstehen und nicht leicht zu berechnen.
2. SD gibt extremen Bewertungen mehr Gewicht und Verlusten, die näher am Mittelwert liegen. Dies liegt daran, dass die Quadrate der Abweichungen, die groß sind, proportional größer als die Quadrate der Abweichungen sind, die vergleichsweise klein sind.
Verwendung von SD:
1. SD wird verwendet, wenn es unser Ziel ist, die Variabilität mit der größten Stabilität zu messen.
2. Wenn extreme Abweichungen die Variabilität zu diesem Zeitpunkt beeinflussen können, wird SD verwendet.
3. SD dient zur Berechnung der weiteren Statistiken wie Korrelationskoeffizient, Standardwerte, Standardfehler, Varianzanalyse, Kovarianzanalyse usw.
4. Wenn die Interpretation der Wertungen in Bezug auf den NPC vorgenommen wird, wird SD verwendet.
5. Wenn wir die Zuverlässigkeit und Gültigkeit von Testergebnissen ermitteln wollen, wird SD verwendet.
Kombinierte Standardabweichung:
Während der Forschungsarbeit entnehmen wir manchmal mehr als eine Stichprobe aus der Bevölkerung. Daher erhalten wir für jede Gruppe oder Probe unterschiedliche SDs. Aber manchmal müssen wir diese Ergebnisse als eine Gruppe interpretieren. Wenn also verschiedene Sätze von Bewertungen zu einem einzigen Los zusammengefasst wurden, ist es möglich, den SD der Gesamtverteilung aus den SD der Untergruppen zu berechnen.
Formel zur Berechnung der kombinierten Standardabweichung oder lautet wie folgt:

N 1, N 2, N n = Anzahl der Punkte in Gruppe-1, Gruppe-2 usw. bis zur n-ten Gruppe.
d = (Mean-M comb ) 'd' wird gefunden, indem M comb vom Mittelwert der betroffenen Gruppe abgezogen wird.
Ebenso werden d 1, d 2 … d n ermittelt .
σ = Standardabweichung der betroffenen Gruppe σ 1, σ 2, σ 3 bedeutet σ der Gruppe 1, Gruppe-2, Gruppe-3 usw.
Beispiel:

Lösung:

Geben Sie nun die Werte in die Formel ein.